
If you’ve scrolled through the web lately and felt like everything online has become strangely repetitive, shallow, or just plain weird, you’re picking up on a real shift. The internet, once a vibrant repository of human ideas, creativity, and messy authenticity, is increasingly filled with generic AI-spun articles, robotic product descriptions, and eerily similar social media takes. This isn’t random—it’s the early warning sign of a profound crisis in artificial intelligence: model collapse.
Generative AI tools like ChatGPT have exploded in popularity, producing content at an unprecedented scale. But in doing so, they’ve begun polluting the very data ecosystem that powers their existence and future generations of AI. As models train on more and more synthetic output, they risk entering a degenerative spiral where intelligence erodes, diversity vanishes, and outputs turn into distorted echoes. In 2026, this phenomenon—backed by landmark research and growing industry concern—is no longer theoretical; it’s actively threatening the trajectory of AI development.

The Dead Internet Pt. 2: Why AI Can’t Stop Eating Itself | by ToxSec | Medium
The Feedback Loop: How AI Is Starving Itself
Model collapse is like a digital version of the classic photocopy degradation. Start with crisp original (human-generated content). Copy it once—still decent. Keep copying copies, and by the tenth generation, details blur. By the hundredth, it’s unrecognizable noise.
Generative AI models are trained on massive internet datasets rich in human expression—nuanced language, cultural references, rare knowledge, and creative outliers (the “long tail”). But as AI-generated content floods the web—estimates suggest it could dominate new online material—the training corpora become contaminated. Future models learn from this “synthetic slop,” forgetting subtle patterns and amplifying errors.
Key 2024 research published in Nature demonstrated this irreversibly: models trained recursively on their own outputs lose fidelity to real distributions, collapsing into gibberish or homogenized mediocrity. Recent 2025-2026 analyses, including warnings from Gartner and Stanford experts, confirm the trend is accelerating. With 84% of organizations planning increased generative AI investment in 2026, the volume of polluted data is set to surge, heightening collapse risks.
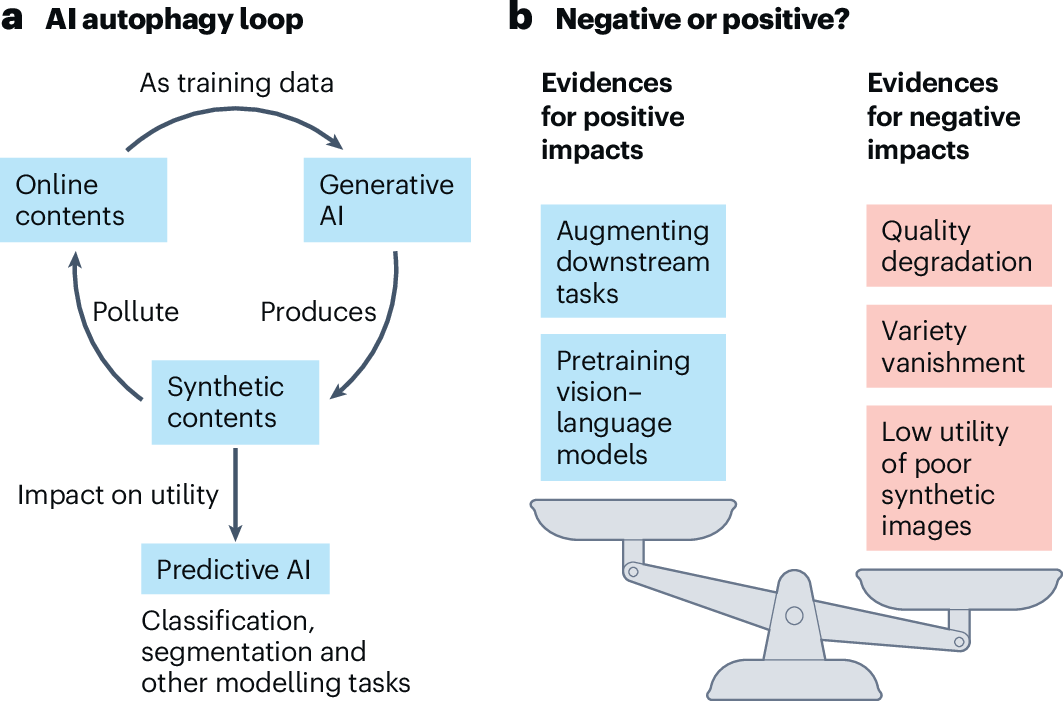
On the caveats of AI autophagy | Nature Machine Intelligence
The Low-Background Steel Parallel: 2022 as AI’s “Atomic Age”
This crisis draws a haunting analogy from history. After the 1945 nuclear tests, radioactive fallout contaminated global steel production, rendering post-war metal useless for sensitive instruments like Geiger counters.
Scientists turned to “low-background steel” from pre-atomic sources—often sunken World War-era battleships preserved underwater. Maurice Chiodo, a researcher at Cambridge’s Centre for the Study of Existential Risk, extends this to AI: the widespread release of ChatGPT in late 2022 is the “nuclear detonation.”
Pre-2022 internet data remains “clean”—pure human creation without synthetic interference. Post-2022 content is increasingly “radioactive,” tainted by AI outputs. As contamination spreads, authentic pre-2022 datasets become a finite, precious resource, much like those scuttled warships.
Widening Inequalities: The Clean Data Divide
Big tech pioneers—OpenAI, Google, and Meta—trained foundational models on the vast, uncontaminated pre-2022 web, gaining an insurmountable edge. Now, as the internet drowns in synthetic content, newcomers face a poisoned well. Smaller developers, researchers, and startups struggle to curate high-quality data, entrenching monopolies.
In 2026, this divide manifests in collapsing AI startups, rapid commoditization of models (new releases lose their edge in weeks via distillation), and warnings of an impending “AI bubble” burst. Techniques like Retrieval-Augmented Generation (RAG) falter when pulling from polluted sources, increasing hallucinations and unsafe outputs.
Signs of Trouble Already Emerging in 2026
The cracks are visible:
- Diminishing returns on scaling: Peak data concerns rise as quality trumps quantity.
- Accuracy collapses in complex tasks, per Apple and other studies.
- Faster model replication: Competitors match state-of-the-art in weeks.
- Industry shifts: Zero-trust data governance gains traction to verify sources.
Stanford predictions for 2026 emphasize “peak data,” smaller efficient models, and curation over brute force. Without clean inputs, progress asymptotes.
Breaking the Cycle: Paths to Recovery
Solutions exist, though they are challenging:
- Mandatory labeling/watermarking of AI content to filter during training.
- Human-in-the-loop curation and synthetic data validation.
- Zero-trust governance emphasizing provenance.
- Preservation of pre-2022 archives and ethical data practices.
Regulations, once resisted, may become essential. Ironically, the innovation-driven AI sector could self-sabotage without oversight.

Conclusion
In 2026, generative AI stands at a crossroads. The same technology that promised boundless creativity risks devouring its foundation through unchecked proliferation of synthetic content. Model collapse isn’t distant doom—it’s an ongoing degradation that could stall breakthroughs, widen inequalities, and turn the internet into a hall of mirrors.
Yet awareness is growing. By prioritizing clean data, transparency, and sustainable practices, the industry can mitigate risks and preserve human ingenuity’s role in AI evolution. The future isn’t doomed to recursion; it depends on whether we act to break the loop before the echoes drown out the originals.
FAQ
What exactly is model collapse in AI?
Model collapse is the progressive degradation of generative AI performance when trained on increasingly synthetic (AI-generated) data. It leads to loss of diversity, amplified errors, and outputs drifting toward mediocrity or nonsense, similar to generational photocopying degradation.
Why is pre-2022 data considered “clean” for AI training?
Pre-2022 data predates widespread generative AI tools like ChatGPT, containing mostly authentic human-created content without synthetic pollution. Post-2022 data is increasingly contaminated, making earlier archives invaluable—like low-background steel before nuclear fallout.
How is model collapse affecting AI development in 2026?
It’s contributing to diminishing returns on new models, rapid commoditization, startup failures, and concerns over an “AI bubble” burst. Techniques relying on web retrieval suffer from polluted sources, and experts predict a shift toward curated, smaller datasets.
Can model collapse be prevented?
Yes, through strategies like watermarking AI content, human-curated datasets, zero-trust governance, and regulations mandating transparency. Mixing high-quality human data with carefully validated synthetic inputs can slow or mitigate the spiral.
Is the AI industry addressing model collapse seriously?
Growing evidence from 2025-2026 research (Nature, Gartner, Stanford) shows increasing focus. Shifts to inference-time scaling, reasoning models, and data sovereignty efforts indicate adaptation, though challenges persist amid rapid adoption.

